

Authors

Integrating Unstructured metadata with Pinecone Hybrid Search can significantly enhance Retrieval Augmented Generation (RAG) systems by improving the retrieval of relevant documents for the Large Language Models (LLMs).
Metadata plays a crucial role in enhancing the efficiency of language model applications and search processes. By providing essential information about documents' content, structure, and context, metadata allows for precisely filtering and categorizing document elements. Unstructured metadata tracks general document information, like filename and file type, and more detailed document-specific information, such as element type.
Pinecone Hybrid Search combines semantic and keyword searches using sparse-dense vectors, enabling more comprehensive and relevant search results. Semantic search, enabled by dense vectors, focuses on finding semantically similar results from the documents. On the other hand, sparse vectors are ideal for keyword searches, indicating the importance of specific words. This dual approach ensures that search results are contextually relevant and precisely matched to query keywords. You can refer to Pinecone's documentation on Understanding Hybrid Search.
The synergy of these technologies provides several advantages:
- Precise Document Search: Unstructured metadata and Pinecone Hybrid Search can accurately match search queries with relevant documents.
- High-Efficiency Retrieval: Leveraging structured metadata with Pinecone's hybrid search technology ensures quick access to relevant information in extensive data collections.
- Easy Metadata Filtering: Unstructured pulls across existing file metadata from systems of record and generates new metadata (e.g. element type, hierarchy, xy coordinates, language, and more). This metadata can be used in conjunction with Hybrid Search to further enhance retrieval.
This combination of Unstructured metadata extraction/generation and Pinecone Hybrid Search offers significant improvements in Retrieval Augmented Generation (RAG) systems. By enhancing search on diverse datasets, these technologies empower RAG systems to produce more accurate and relevant results. This blog post demonstrates how to extract and generate metadata using Unstructured and integrate it with Pinecone Hybrid Search for enhanced data retrieval capabilities. You can follow the code in this Google Colab notebook.
Extracting Text and Metadata from PDF Documents
The process begins with the transformation of data from PDF documents. Utilizing the partition_pdf method, we can render a PDF into clean JSON, broken down to individual document elements. This method identifies and separates logical bodies of text within a document, such as text, tables, and images. The ability to precisely render these elements is crucial in generating a detailed metadata repository that enhances the accuracy of data retrieval.
pdf_filename = "alphabet_10K_2022.pdf"
from unstructured.partition.pdf import partition_pdf
elements = partition_pdf(pdf_filename, strategy="hi_res", hi_res_model_name=”yolox”,
infer_table_structure=True,)
elements[0].metadata
# Output
ElementMetadata
coordinates=CoordinatesMetadata(points=((60.208333333333336, 0),
(60.208333333333336, 129.27083333333334), (451.5625, 129.27083333333334), (451.5625, 0)),
system=<unstructured.documents.coordinates.PixelSpace object at 0x32f6cfd60>),
data_source=None,
filename='alphabet_10K_2022_abbrev.pdf',
file_directory='pdf',
last_modified='2023-11-03T12:44:50',
filetype='application/pdf',
attached_to_filename=None,
parent_id=None,
category_depth=None,
image_path=None,
languages=None,
page_number=1,
page_name=None,
url=None,
link_urls=None,
link_texts=None,
links=None,
sent_from=None,
sent_to=None,
subject=None,
section=None,
header_footer_type=None,
emphasized_text_contents=None,
emphasized_text_tags=None,
text_as_html=None,
regex_metadata=None,
max_characters=None,
is_continuation=None,
detection_class_prob=None)Metadata Selection for Storage and Retrieval in Pinecone
After transforming the PDF into JSON with relevant metadata using Unstructured, this data is converted into a Pandas DataFrame. This transformation from JSON into DataFrame format will be useful in the later step when we bulk-upsert data into Pinecone Index. The DataFrame also provides a structured and intuitive way to organize and access the documents in the Pinecone vector database.
Unstructured metadata provides advanced features, such as “parent_id”, representing document hierarchy that could be useful for context-aware chunking in a RAG architecture. For this example, however, we select a few metadata we want to use for storage and retrieval. This includes Element Type, Filename, Date Modified, Filetype, Page Number, and Text. Each type of metadata serves a specific purpose:
- Element Type helps categorize the data for more efficient retrieval.
- Filename and Date Modified offer context and version control.
- Filetype and Page Number provide structural information.
- Text is the core content used for retrieval and LLMs.
# Convert JSON output into Pandas DataFrame
data = []
for c in elements:
row = {}
row['Element Type'] = type(c).__name__
row['Filename'] = c.metadata.filename
row['Date Modified'] = c.metadata.last_modified
row['Filetype'] = c.metadata.filetype
row['Page Number'] = c.metadata.page_number
row['text'] = c.text
data.append(row)
df = pd.DataFrame(data)
df.head()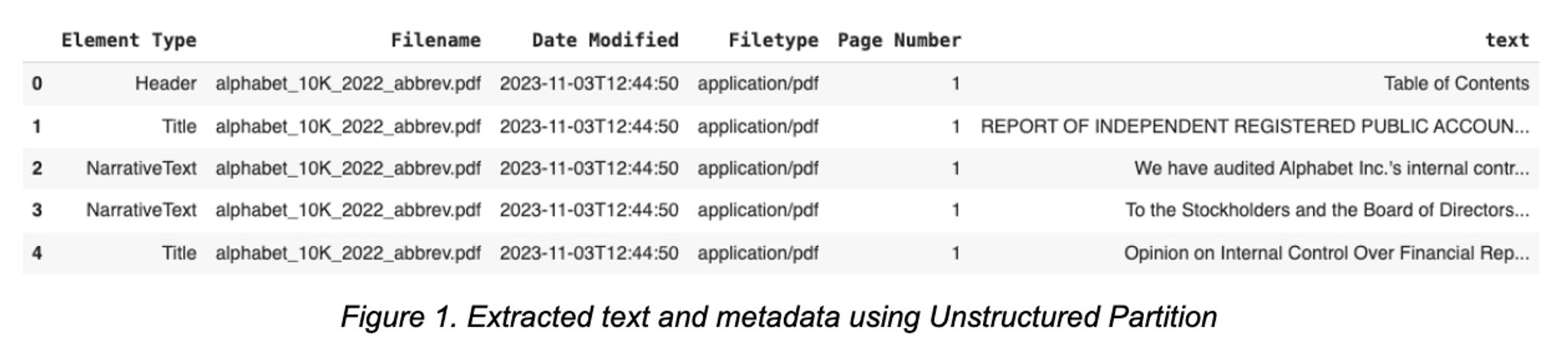
Storing Documents by Elements Metadata
The bifurcation of document storage into Sparse and Dense data storage in Pinecone Hybrid Search is designed to optimize search and retrieval processes. This dual strategy ensures that text and metadata are stored and accessed most efficiently for their specific purposes, thereby enhancing the overall effectiveness of the RAG architecture.
Storage of documents is divided into two categories:
- Sparse Data Storage: Here, we store metadata like Filename, Element Type, and Page Number. This approach is akin to creating an index that helps quickly reference and retrieve documents.
- Dense Data Storage: This involves storing vectorized text. Vectorization transforms text data into a numerical format, which are essential for semantic search. The dense data is crucial in the search capability beyond the keywords matching.
Initialize and Create Pinecone Index
This step explains how to initialize and create a Pinecone index for storing document data. First, you will need to generate a Pinecone API key. The process involves creating a new Pinecone project, defining the index name, and creating the index with specific dimensions and metrics. The code below demonstrates how to: initialize a connection to Pinecone, check for existing indexes, create a new index, and ensure its readiness.
Note: as of Jan 16, 2024, Pinecone has introduced a new API with the release of pinecone-client version 3.0.0. For a comprehensive list, see the Python client v3 migration guide.
from pinecone import Pinecone, PodSpec
# Instantiate Pinecone instance with API key
pc = Pinecone(api_key=os.environ['PINECONE_API_KEY'])
# Create a pod index. By default, Pinecone indexes all metadata.
pc.create_index(
name=os.environ['PINECONE_INDEX_NAME'],
dimension=384,
metric='dotproduct',
spec=PodSpec(
environment='gcp-starter',
pod_type='p1.x1',
pods=1, ))
# Show the information about the newly-created index
pc.describe_index(os.environ['PINECONE_INDEX_NAME'])
# {'dimension': 384,
'host': '<<host>>.svc.gcp-starter.pinecone.io',
'metric': 'dotproduct', # pinecone hybrid search only works with
dotproduct
'name': 'metadata-hybrid-search',
'spec': {'pod': {'environment': 'gcp-starter',
'pod_type': 'starter',
'pods': 1,
'replicas': 1,
'shards': 1}},
'status': {'ready': True, 'state': 'Ready'}}Define Sparse and Dense Vectors
Sparse vectors, created using the BM25Encoder, are particularly useful for keyword-based data. Dense vectors, generated using SentenceTransformer models, capture the semantic essence of the text.
# sparse vector
from pinecone_text.sparse import BM25Encoder
bm25 = BM25Encoder()
bm25.fit(df['text'])
# dense vector
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
'multi-qa-MiniLM-L6-cos-v1',
device='cpu'
)Upload the Documents to the Pinecone Index
Finally, we upload the documents to the Pinecone index. We batch the documents (metadata and text batches), encode them into sparse and dense vectors, and then insert them into the Pinecone index. Using tqdm for progress visualization and the step-by-step upsert process, we ensure efficient and organized data upload.
from tqdm.auto import tqdm
batch_size = 32
# Loop through the DataFrame 'df' in batches of size 'batch_size'
for i in tqdm(range(0, len(df), batch_size)):
i_end = min(i+batch_size, len(df)) # Determine the end index of the current batch
df_batch = df.iloc[i:i_end] # Extract the current batch from the DataFrame
df_dict = df_batch.to_dict(orient="records") # Convert the batch to a list of dictionaries
# Create a batch of metadata by concatenating all columns
# except 'Filetype', 'Element Type', and 'Date Modified'
meta_batch = [
" ".join(map(str, x)) for x in df_batch.loc[
:, ~df_batch.columns.isin(['Filetype', 'Element Type', 'Date Modified'])
].values.tolist()
]
# Extract the 'text' column from the current batch as a list
text_batch = df['text'][i:i_end].tolist()
# Encode the metadata batch using the bm25 algorithm to create sparse embeddings
sparse_embeds = bm25.encode_documents([text for text in meta_batch])
# Encode the text batch using a model to create dense embeddings
dense_embeds = model.encode(text_batch).tolist()
# Generate a list of IDs for the current batch
ids = [str(x) for x in range(i, i_end)]
# Initialize a list and iterate over each item in the batch to prepare the upsert data
upserts = []
for _id, sparse, dense, meta in zip(ids, sparse_embeds, dense_embeds, df_dict):
upserts.append({
'id': _id,
'sparse_values': sparse,
'values': dense,
'metadata': meta
})
# Connect to the Pinecone index and upsert the batch data
index = pc.Index(host=pinecone_host)
index.upsert(upserts)Retrieval and Filtering with Pinecone Hybrid Search
The ability to retrieve exactly what's needed — such as specific numerical data from tables — is arguably the most crucial step in building an accurate, reliable RAG system. It's not just about finding data; it's about finding the right data, quickly and accurately.
Pinecone Hybrid Search facilitates efficient data storage and provides advanced retrieval and filtering techniques. For instance, users can filter retrieved data based on Element Type, such as Tables, which is particularly useful in scenarios requiring specific data formats.
Pinecone facilitates this selective retrieval by allowing users to attach metadata key-value pairs to vectors in an index. When querying, users can specify filter expressions based on this metadata. This enables precise and relevant search results, like filtering for only “Table” elements in a set of documents. For more details, refer to Pinecone's documentation on Filtering with Metadata.
Basic Retrieval
This code below demonstrates the retrieval of documents from the Pinecone index leveraging a combination of sparse and dense vectors. A query is first vectorized into sparse and dense formats and then passed into the Pinecone index query function. This method returns the top results that best match the query regarding semantic relevance and keyword match.
query = "What is the cash and cash equivalent in 2022?"
# create sparse and dense vectors
sparse = bm25.encode_queries(query)
dense = model.encode(query).tolist()
# search
result = index.query(
top_k=5,
vector=dense,
sparse_vector=sparse,
include_metadata=True
)Filtering Retrieval for Tables Only
Finally, we will demonstrate how to use metadata filtering to search exclusively for “Table” elements. This feature is particularly useful for applications where tables, such as academic research or business analytics, are essential for data analysis. By enabling searches targeted solely at “Table” elements, users can efficiently extract data like research statistics or financial figures from various documents.
The process is similar to the standard retrieval but requires an additional metadata filter. This ensures that the search results are confined to documents that match the query semantically and specifically belong to the "Table" category.
# search with metadata filter to show Table only
result_with_filter = index.query(
top_k=2,
filter={
'Element Type': 'Table'
},
vector=dense,
sparse_vector=sparse,
include_metadata=True
)Conclusion
Combining Unstructured text and metadata extraction with Pinecone Hybrid Search in RAG systems offers a unique data storage and retrieval approach. This combination enhances the accuracy and relevance of the information retrieved and streamlines the process, making it more efficient and user-friendly. As we continue to delve deeper into the era of big data, such innovations will play a critical role in harnessing the full potential of unstructured datasets.
Providing the rich metadata extracted by Unstructured to Pinecone’s Hybrid Search unlocks even more accurate and efficient retrieval, a key foundation for building robust RAG systems. To name a few, this metadata includes things like granular element type, document name, source URL, page number, languages used, date created, date last modified, and hierarchy. When we feed this rich data to Hybrid Search, we narrow responses to a user’s question to pinpoint the precise relevant content. To unlock this search across all their documents, users need an ingestion and preprocessing workflow, pulling and feeding through documents in several different formats and locations. In addition to metadata generation, users will need element extraction and chunking. Fortunately, for all of this, Unstructured has you covered. It supports 25 different file types and 30+ source/destination connectors. It also has smart chunking capabilities to make sure the entries in your Pinecone database are always cohesive and logically complete entities (no critical, missing content).
About Pinecone
Pinecone has built the first vector database to enable the next generation of artificial intelligence (AI) applications in the cloud. Its engineers built ML platforms at AWS, DataBricks, Yahoo, Google, and Splunk, and its scientists published more than 100 academic papers and patents on machine learning, data science, systems, and algorithms. Pinecone operates in Silicon Valley, New York, and Tel Aviv. For more information, see https://www.pinecone.io.
About Unstructured
Unstructured is the leading provider of LLM data preprocessing solutions, empowering organizations to transform their internal unstructured data into formats compatible with large language models. By automating the transformation of complex natural language data found in formats like PDFs, PPTX, HTML files, and more, Unstructured enables enterprises to leverage the full power of their data for increased productivity and innovation. With key partnerships and a growing customer base of over 35,000 organizations, Unstructured is driving the adoption of enterprise LLMs worldwide. To learn more, connect with us directly in our community Slack.
FAQ
What is the difference between sparse and dense vectors in hybrid search?
Sparse vectors represent text as high-dimensional arrays where most values are zero, making them effective for exact keyword matching. Dense vectors are lower-dimensional numerical representations that capture semantic meaning, allowing retrieval of conceptually related content even when exact terms differ. Hybrid search combines both to return results that are both keyword-relevant and contextually appropriate.
Why does metadata filtering matter in RAG systems?
Without metadata filtering, a retrieval system returns the most semantically similar chunks regardless of their document type, location, or structure, which can introduce irrelevant or misleading context into an LLM's response. Filtering by metadata fields like element type, page number, or file source narrows results to the most applicable content, improving both precision and answer quality.
When should you use hybrid search instead of pure semantic search?
Hybrid search is the better choice when queries involve specific terms, figures, or identifiers that semantic search might miss due to paraphrasing or embedding compression. It is particularly useful for financial documents, legal text, or technical reports where exact keyword matches carry as much weight as contextual relevance.
How does Unstructured extract metadata from documents like PDFs?
Unstructured uses its partition_pdf method with high-resolution models to identify and separate logical document elements such as text blocks, tables, and images. For each element, it automatically generates metadata including element type, page number, filename, file type, last modified date, coordinates, language, and document hierarchy identifiers like parent_id. This metadata is available immediately as structured output and can be passed directly into a vector database like Pinecone.
How does Unstructured's chunking capability support Pinecone-based RAG pipelines?
Unstructured includes smart chunking that respects document structure, ensuring each chunk stored in a vector database represents a logically complete unit rather than an arbitrary text split. This prevents critical content from being cut off mid-sentence or mid-table, which directly improves retrieval quality. Combined with Unstructured's support for 25 file types and 30+ source and destination connectors, it provides a complete ingestion pipeline from raw documents to indexed, searchable vectors.


