
Authors

Imagine this concept applied to a textbook or a user manual. A richly detailed image can convey nuances that text alone may struggle to express. Using the Unstructured Platform, we can leverage frontier multimodal large language models (LLMs) to generate detailed image descriptions. These descriptions can then be seamlessly integrated into RAG workflows, enhancing the contextual depth and quality of the generated outputs. Then, when one of these image descriptions appears in a chunk that was retrieved as context for a RAG response, we can recreate the image, using the base64 encoding we stored in the chunk's metadata!
In this notebook, we'll explore how leveraging visual data in RAG can unlock new possibilities for enriched, context-aware responses. Let's dive into the intersection of visual and textual AI for a more dynamic approach to information synthesis!
For this demo, we will use the widely read The Illustrated Transformer by Jay Alammar to perform visually-enriched QnA. This blog post is famous for how well it illustrates the concepts behind the ubiquitous transformer architecture.

After running a workflow to extract text and base64 encoded images from a pdf of this blog post, we demonstrate a few example queries:
Example 1: Understanding Self-Attention
Output:
Self-Attention is a concept from the Attention is All You Need paper. At a high level, in the context of an encoder structure for machine learning, each word in a sentence is processed through a self-attention layer first, and then a feed-forward neural network.
During the self-attention process, each input word (represented by a vector) is transformed into three smaller vectors: a Query vector, a Key vector, and a Value vector. This is done by multiplying the input vector with three distinct matrices, which are trained during the training process.
The purpose of these vectors is to help the network to understand the context and the relevance of a word in a given position within the sentence by comparing it (the Query) with other words (the Keys) and adjusting the original word's encoded representation (the Value) accordingly.
In other words, self-attention is a process that helps the neural network pay "attention" to different words within the sentence, identifying and preserving their context based on their relationships with the other words.
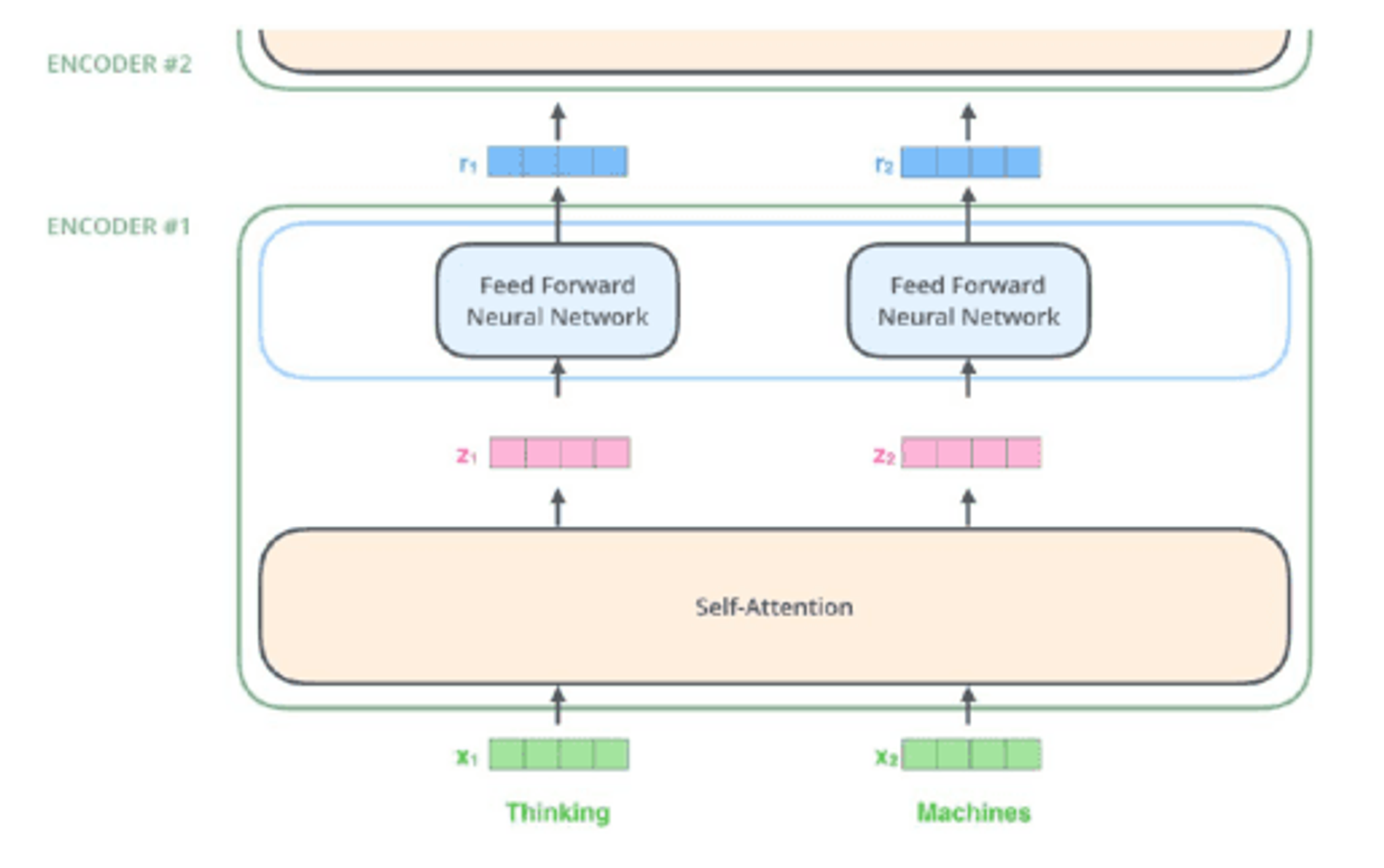
The diagram illustrates a two-layer encoder structure. At the bottom, there are two input tokens labeled 'x1' and 'x2' with the words 'Thinking' and 'Machines' respectively. These inputs are processed through a 'Self-Attention' layer. The outputs from this layer are labeled 'z1' and 'z2'. These are then fed into two separate 'Feed Forward Neural Network' blocks. The outputs from these networks are labeled 'r1' and 'r2'. The entire process is encapsulated within two encoder layers labeled 'ENCODER #1' and 'ENCODER #2'.
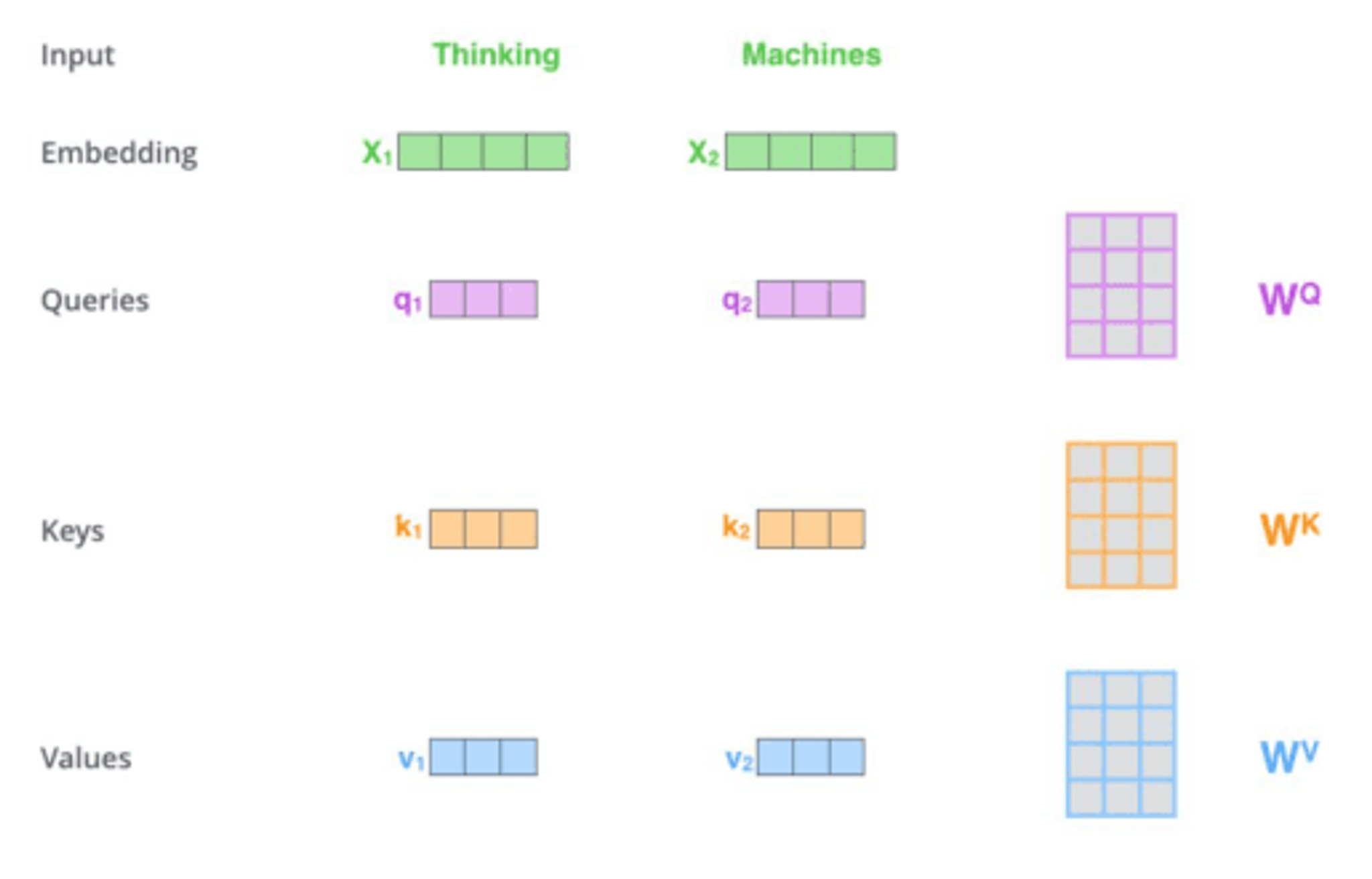
The diagram illustrates the process of transforming input words into embeddings, queries, keys, and values. It includes the following elements:
- Input: 'Thinking' and 'Machines' in green.Embedding: 'X1' and 'X2' in green with corresponding boxes.
- Queries: 'q1' and 'q2' in purple with corresponding boxes, and a matrix labeled 'WQ'.
- Keys: 'k1' and 'k2' in orange with corresponding boxes, and a matrix labeled 'WK'.
- Values: 'v1' and 'v2' in blue with corresponding boxes, and a matrix labeled 'WV'.
Example 2: Understanding the Transformer Decoder
Output:
A transformer decoder is a part of the transformer model used in sequence-to-sequence tasks like language translation. It receives the processed input from the encoder side, which is transformed into a set of attention vectors, K and V. These vectors are used in its "encoder-decoder attention" layer, which helps it focus on relevant parts of the input sequence.
In the decoding phase, each step outputs an element from the output sequence (for instance, an English translation sentence). This process is repeated until a special symbol is reached, indicating the end of the output. The output of each step is inputted to the next time step's decoder, passing up the decoding results similarly to the encoders. The decoder inputs also undergo embedding and positional encoding to indicate each word's position.
The decoder structure aligns with the encoder's with identical layers (but they don't share weights). It's essentially a stack of multiple layers of identical decoders (number may vary).
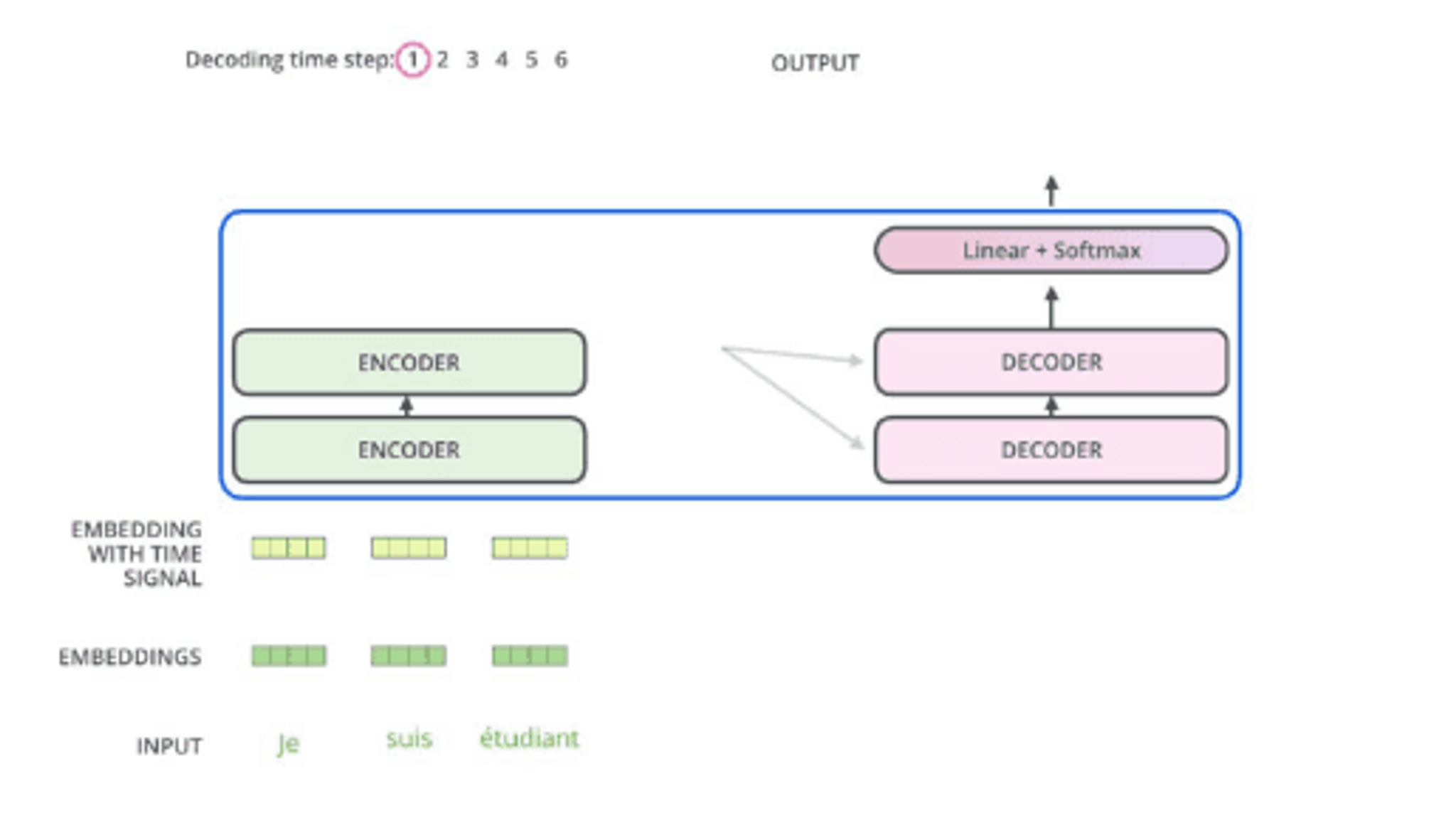
The diagram illustrates a sequence-to-sequence model with encoders and decoders.
- At the top, it shows 'Decoding time step: 1 2 3 4 5 6 OUTPUT' with '1' circled.
- The main section is a box containing two 'ENCODER' blocks on the left, connected by an arrow, and two 'DECODER' blocks on the right, also connected by an arrow. An arrow points from the encoders to the decoders.
- Above the decoders, there is a 'Linear + Softmax' block with an upward arrow indicating output.
- Below the main section, there are 'EMBEDDING WITH TIME SIGNAL' and 'EMBEDDINGS' represented by small green and yellow blocks.
- At the bottom, the 'INPUT' is shown as 'Je suis étudiant'.

The diagram illustrates a transformation process.
- On the left, there is a green box labeled 'INPUT' containing the French words 'Je suis étudiant'.
- An arrow points to a central box labeled 'THE TRANSFORMER' with a red flame-like design.
- Another arrow points from the central box to a purple box labeled 'OUTPUT' containing the English words 'I am a student'.
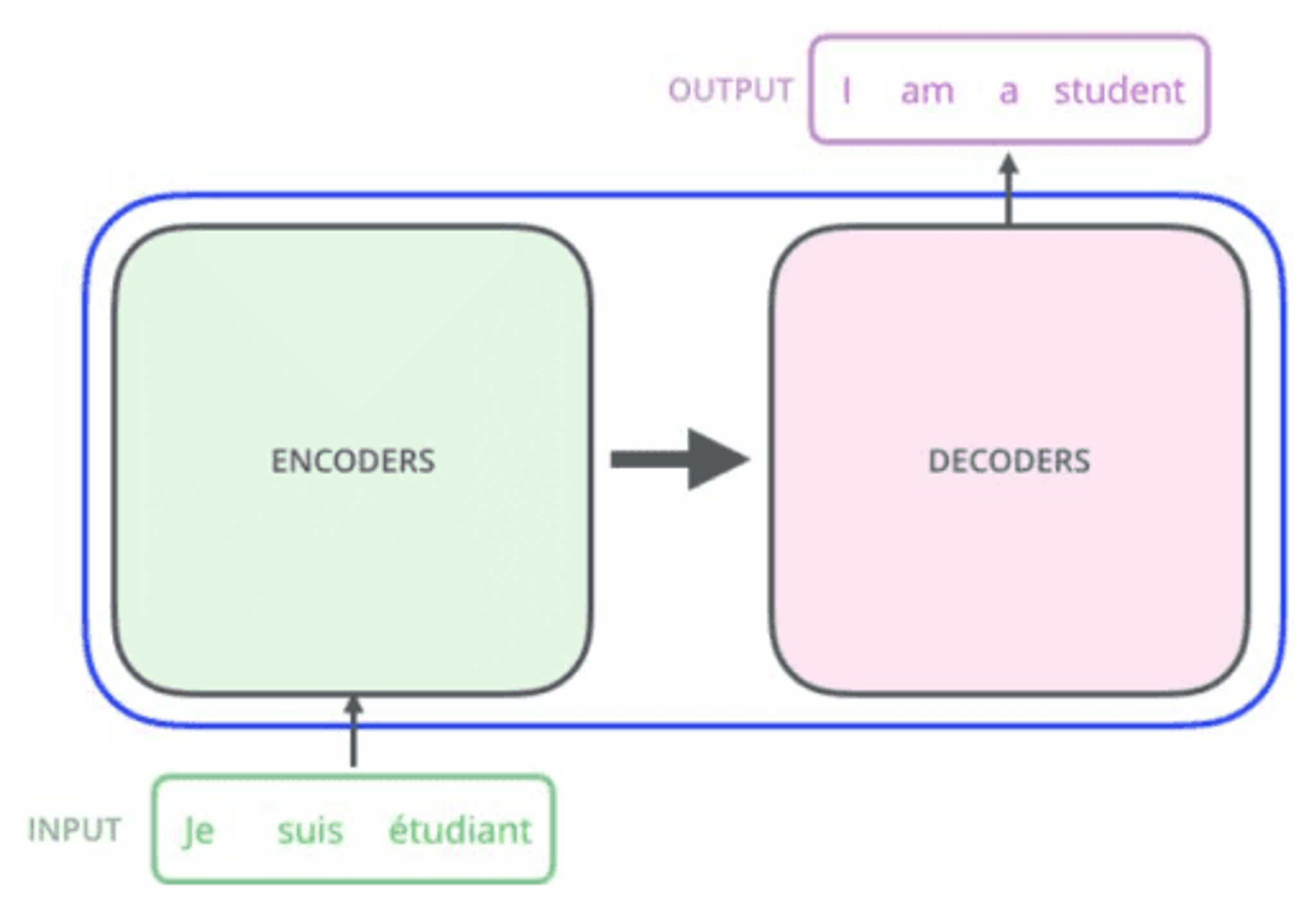
The diagram illustrates a translation process using encoders and decoders. On the left, there is a green box labeled 'ENCODERS' with an arrow pointing to a pink box labeled 'DECODERS' on the right. Below the encoders, there is an input text in green: 'INPUT Je suis étudiant'. Above the decoders, there is an output text in purple: 'OUTPUT I am a student'.
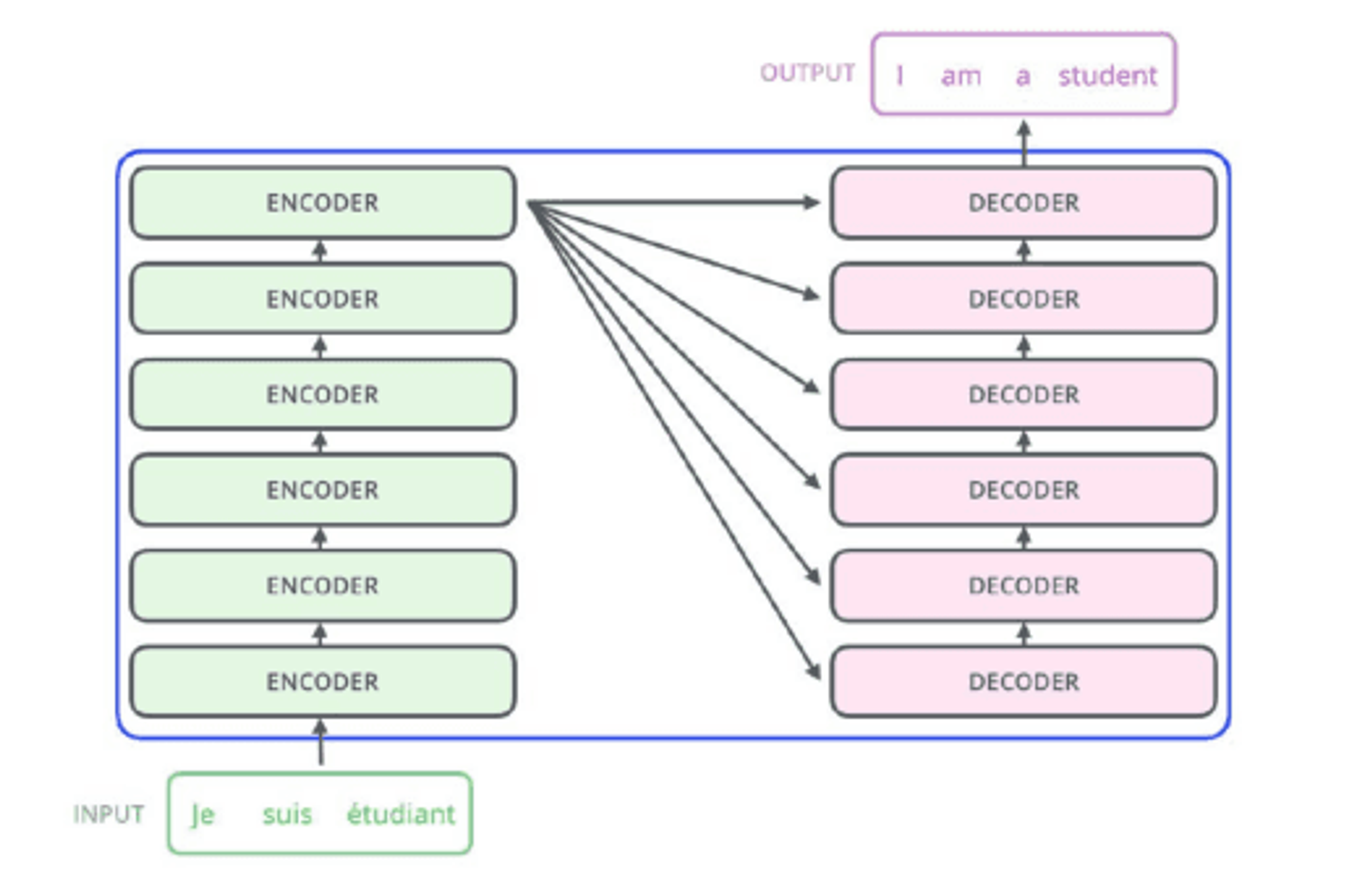
This is a diagram illustrating an encoder-decoder architecture.Text in the diagram:
- INPUT: Je suis étudiant
- OUTPUT: I am a student
The left side contains five boxes labeled 'ENCODER' stacked vertically, connected with arrows indicating a sequential process. The right side contains five boxes labeled 'DECODER' stacked vertically, also connected with arrows. Arrows from the encoders point to the decoders, indicating the flow of information from the encoder to the decoder.
Try this notebook out with your own files with images you'd like to see in RAG responses! You can get started with Unstructured Platform with a 14 day free trial!


