Effortless Document Extraction: A Guide to Using Unstructured API and Data Connectors
Jul 21, 2023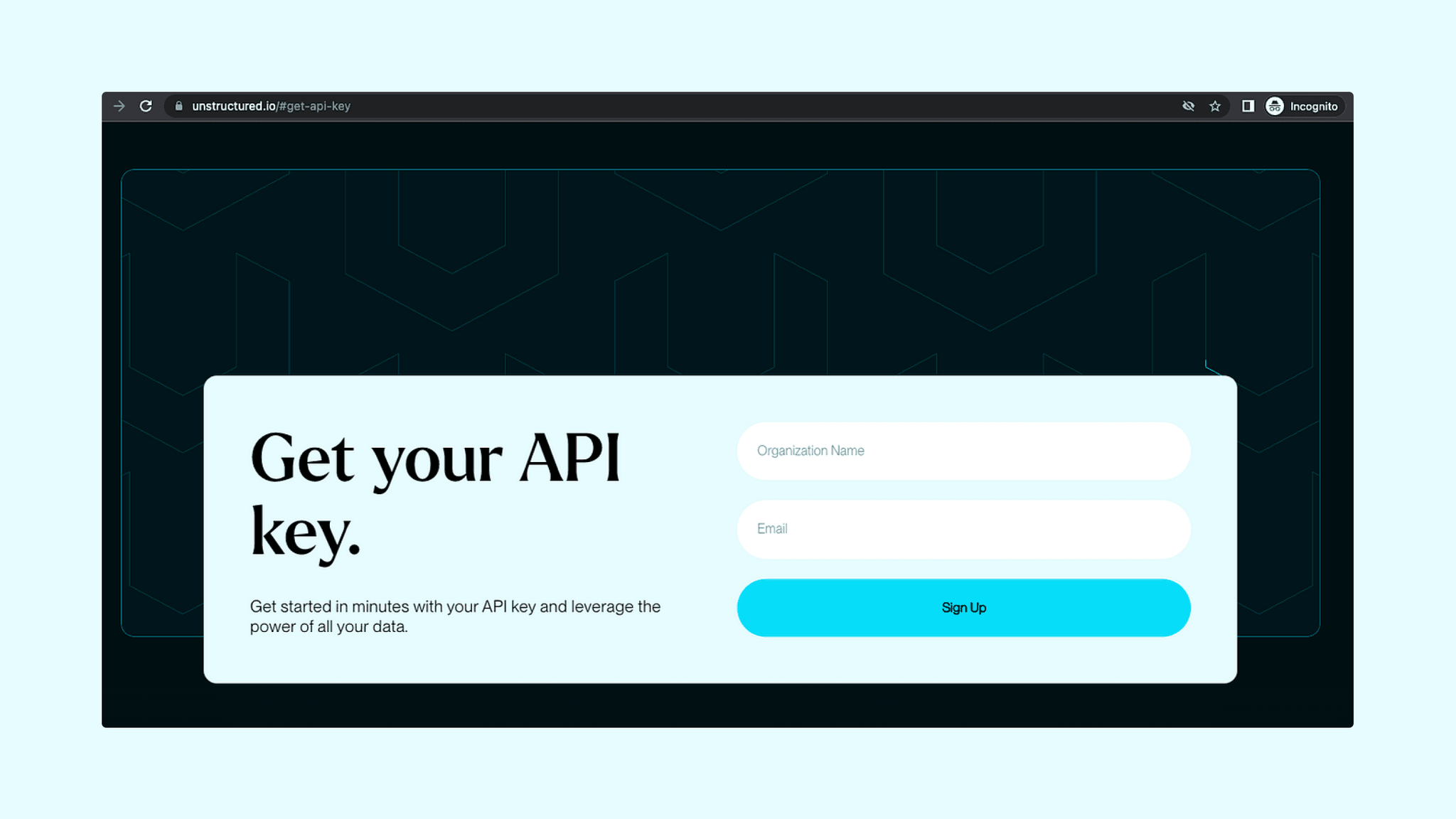
Authors

Enter Unstructured.io, a powerful tool to extract and efficiently transform structured data. With sixteen and counting pre-built connectors, the API can easily integrate with various data sources, including AWS S3, GitHub, Google Cloud Storage, and more.
In this guide, we’ll cover the advantages of using the Unstructured API and Connector module, walk you through a step-by-step process of using it with the S3 Connector as an example, and show you how to be a part of the Unstructured community.
Why Use Unstructured API?
Use cases for the Unstructured open-source library and API are vast; the possibilities are endless, from analyzing customer feedback in real time to extracting insights from large document repositories. While the Unstructured open-source library offers robust functionality, using the Unstructured API brings several compelling advantages:
- Ease of Use: Managing dependencies is unnecessary with the API. All you need is an API key, and you’re ready to go.
- Scalability: Unstructured API can handle large volumes of data, making it perfect for enterprise-scale projects.
- Continuous Updates: As a hosted service, the API benefits from constant updates and improvements without requiring manual updates.
To show how easy it is, we’ll walk you through using Unstructured API with S3 Connector step-by-step.
Guide to Using Unstructured API
Before we start, you will need the following:
- An Unstructured API Key and unstructured-ingest library installed
- An AWS S3 bucket with documents you want to process
- Basic knowledge of command-line operations
Step-by-Step Process:
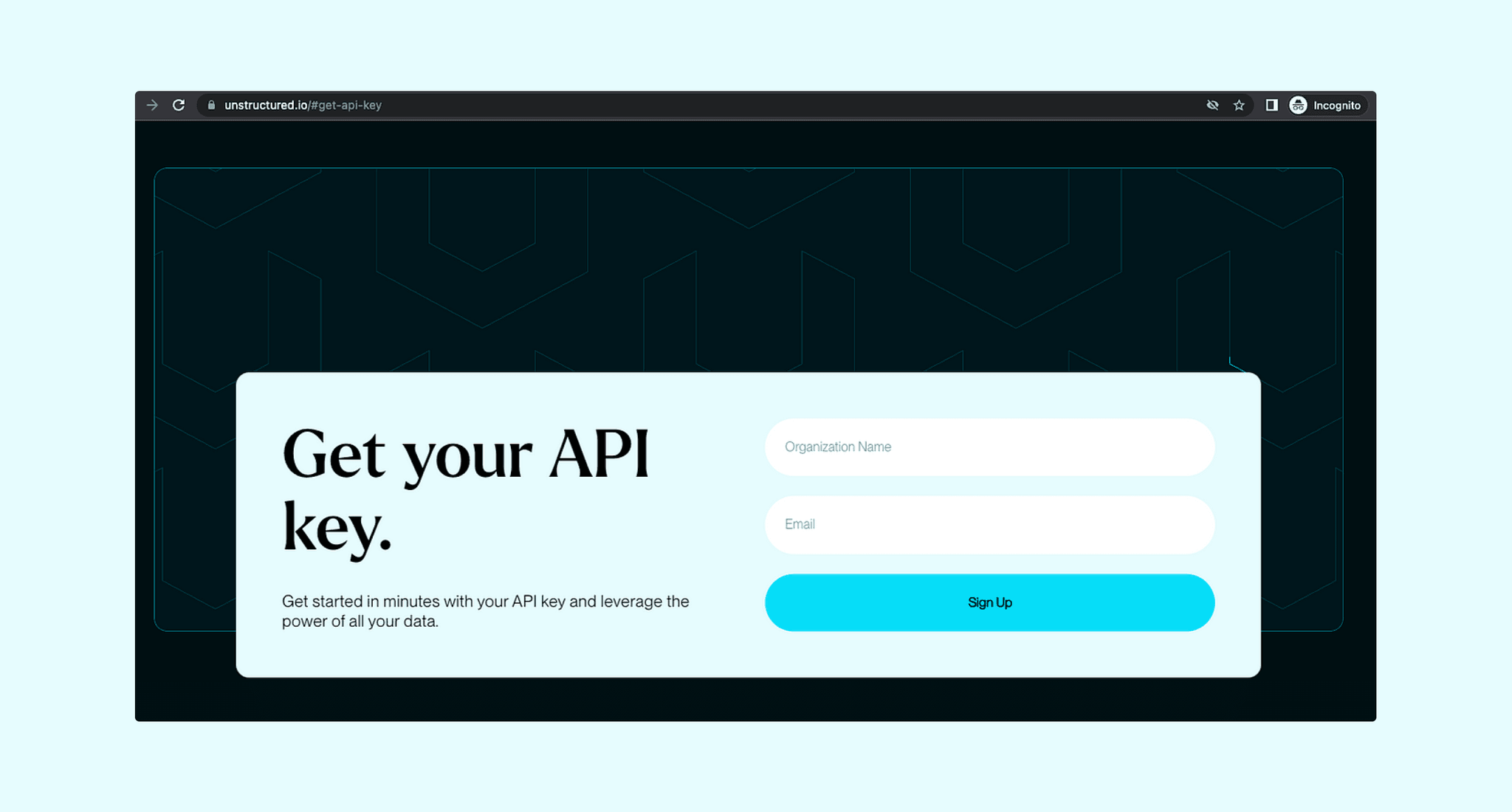
- Get your Unstructured API Key
First, request an API Key by entering your `Organization Name` and `Email` on the request form. This key is your passport to the powerful features of the Unstructured API.
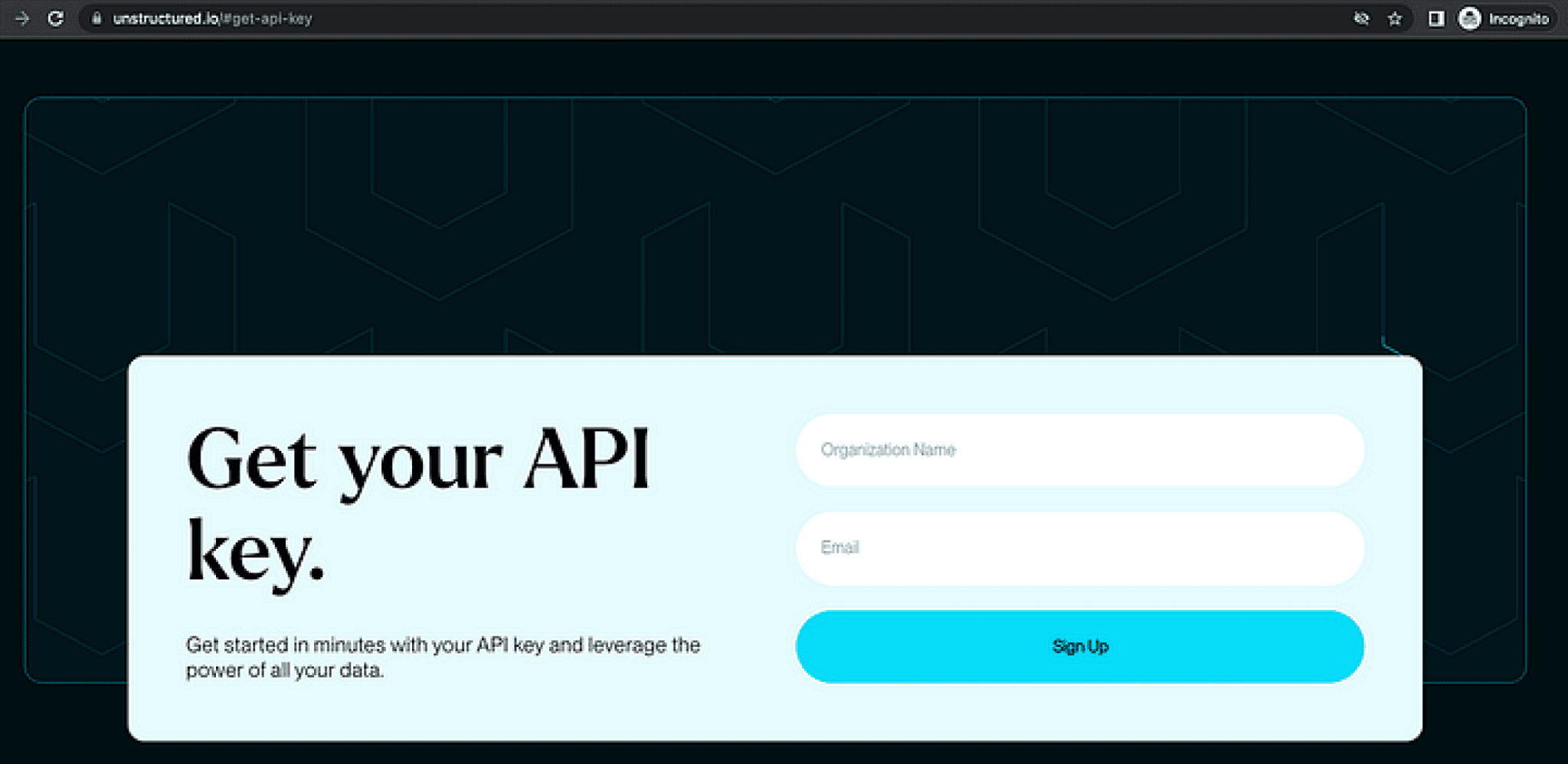
Unstructured API Key Request Form
2. Explore the Pre-Built Data Connectors
The ability to connect with various data sources is crucial in data processing. Unstructured’s Connectors module is designed to provide this flexibility, allowing you to seamlessly integrate your preprocessing pipeline with your preferred data storage platforms.
The Connector module enables you to batch-process all your documents and store structured outputs locally on your file system. This module also supports various connectors designed for a specific data storage platform.
Currently, the Unstructured API supports over a dozen pre-built connectors, each designed to integrate seamlessly with different data sources. These include AWS S3, Google Cloud Storage, Azure Blob Storage, and more. This guide will focus on the S3 Connector as an example.
3. Run Unstructured API with the S3 Connector
With your API key and S3 bucket ready, it’s time to run the Unstructured API. To run the `unstructured-ingest` command, you need to install the unstructured open-source library that can be easily obtained from this GitHub repository.
Simply follow the instructions in the repository to install the library and start using the API command easily. As stated on the installation notes, please make sure to install the following extras when installing unstructured, needed for the following command:
pip install "unstructured[s3,pdf]"
This command will process the documents in your S3 bucket:
unstructured-ingest s3 \ --remote-url s3://utic-dev-tech-fixtures/small-pdf-set/ \--anonymous \--structured-output-dir s3-small-batch-output \--num-processes 8 \--api-key <<YOUR-API-KEY> \--partition-by-api
Explanations:
- Include --api-key from the earlier step in your API call.
- Use the --partition-by-api flag to indicate running the partition through API rather than the library.
- Specify --num-processesto distribute the workload across multiple processes.
- Use --anonymousto make an API request to S3 without local AWS credentials.
- Set the output directory using --structured-output-dirparameter.
4. Review the final output
Once the command completes, you’ll find the structured outputs in your local file system. These files contain the extracted information from your unstructured data, ready for analysis or further processing.
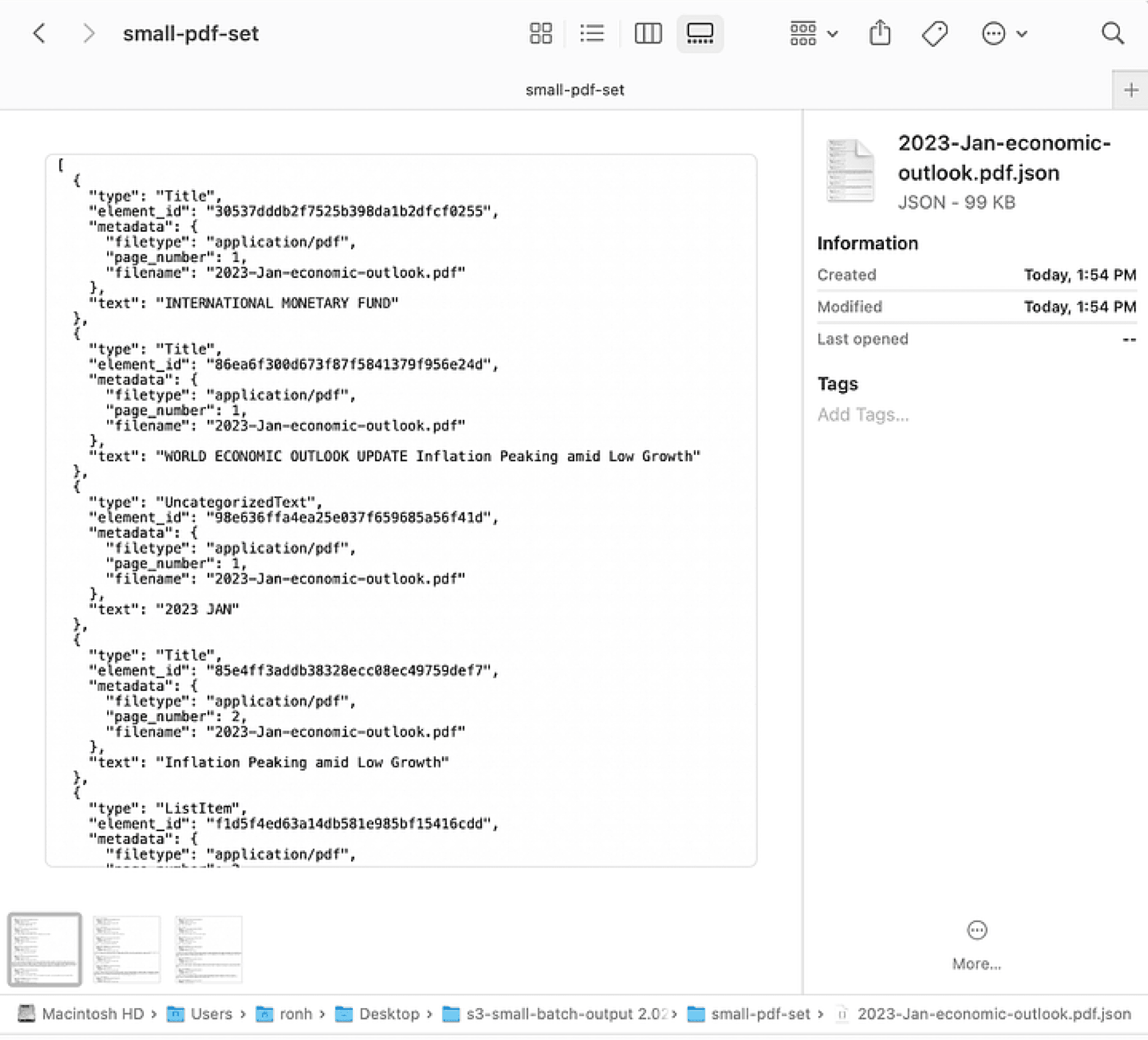
The PDF parser output in JSON format
Looking ahead, Unstructured is developing a downstream connector to write back to AWS S3. This feature will allow you to store the output directly onto S3, streamlining your data pipeline. If you need to store the outputs in an S3 bucket, you can now use the AWS S3 CLI to store the output in your S3 bucket.Join the Unstructured Community GroupReady to get started? Request your API key today and unlock the power of Unstructured API and Connectors. And join the Unstructured community group to connect with other users, ask questions, share your experiences, and get the latest updates. We can’t wait to see what you’ll build.


