
Authors

In fact, the secret in the NLP community is that data scientists are still building artisanal, one-off data connectors and preprocessing pipelines to utilize natural language data with machine learning models.
Data scientists hate dealing with these data engineering bottlenecks, and for good reason, because there is next-to-no tooling available to help them prep their data for machine learning.
We knew to truly take advantage of LLMs we had to figure out how to connect, transform and stage any natural language data in any format at speed and at scale.
So we built Unstructured to do just that.
Providing Data for the LLM Revolution
When we got started in July of 2022, we set out to create an open source toolkit to provide clean training and evaluation data for the types of NLP projects that were common at the time, such as custom NER and relation extraction models. We focused on developing cleaning functions to produce high quality input, integrations with labeling tools such as Argilla, and staging code to make it easy to pass data to models from HuggingFace.
No more than a few weeks after we released the initial version of our open source library in September 2022, ChatGPT launched and completely upended the NLP landscape. Suddenly, there were thousands of open source developers wanting to chat with their data, and the unstructured library was perfectly positioned to help. While we do still support traditional NLP workflows, we shifted our focus toward integrating with tools in the LLM stack, including vector databases like Weaviate and LLM orchestration frameworks like LangChain. Today, we are a key component in the emerging LLM tech stack, with over 700,000 PyPI downloads and usage across more than 100 companies and 2,400 GitHub repos.
What Do We Offer?
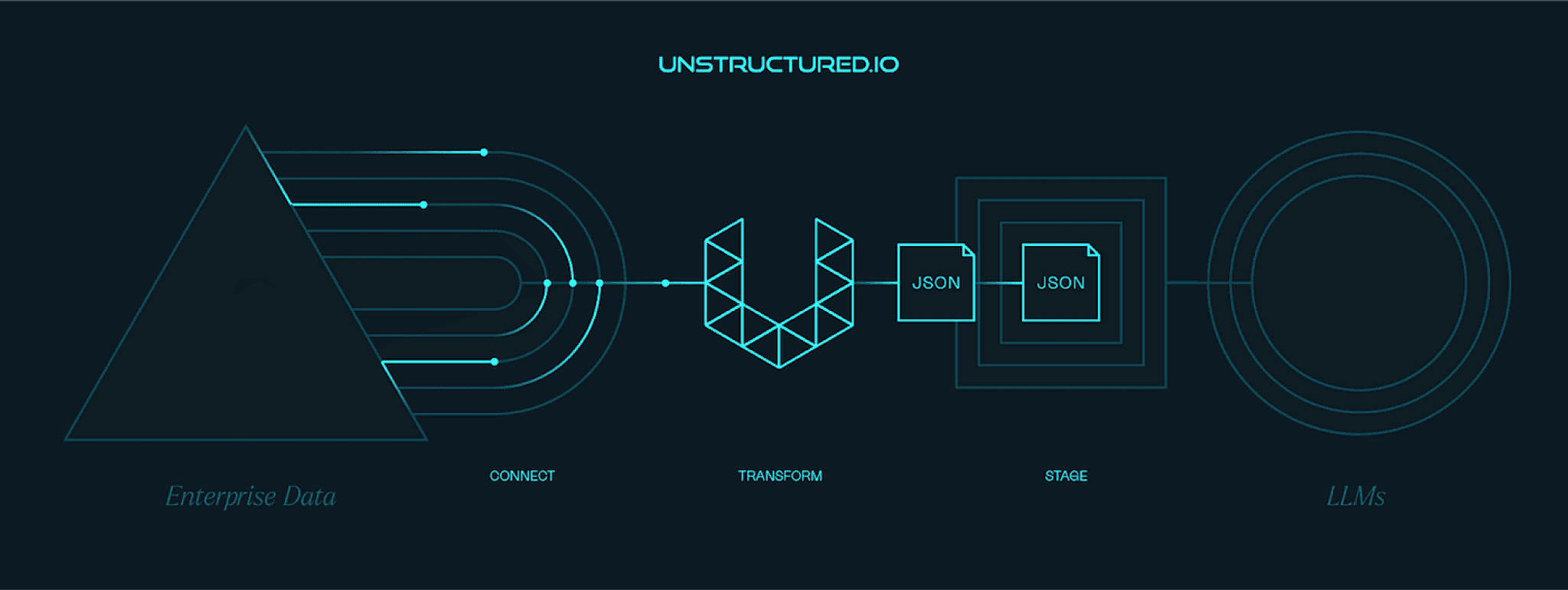
We make it easy for developers and enterprises to utilize their natural language data in conjunction with LLMs, regardless of file type, document layout, or location. Users can now simply run any file containing natural language through our preprocessing pipelines and receive back data in a format ready for LLMs. Organizations can finally leverage their data at a speed and ease previously unimaginable.
Getting Started
Leverage the power of your data with our open source libraries or get started with your API key.
Open Source
Our open source libraries on Github or Google Collab provide developers everything they need to pre-process data for an LLM prototype. This includes upstream data connectors to a growing list of over a dozen sources ranging from Google Cloud Storage to Slack; partitioning functions that extract and normalize text for 20+ document types; and staging functions for easy integration with downstream components such as vector databases.
API Key
Our API provides a turnkey solution for users who want to jump straight into their LLM application without worrying about setting things up themselves. Simply post a document to the API and get back a clean JSON ready for use in your LLM application.
Join Our Community
Join our community Slack to discuss questions and use cases directly with our engineering team. We’re constantly improving and love to hear feedback. If you’re a company and have internal data you’d like to unlock for LLMs, reach out to us.


